Jeroen Bosman and Bianca Kramer, Utrecht University, July 2020
Accompanying spreadsheet: https://tinyurl.com/green-OA-policies
Introduction
We witness increased interest in the role of green open access and how it can contribute to the goals of open science. This interest focuses on immediacy (reducing or eliminating embargoes) and usage rights (through open licenses), as these can contribute to wider and faster dissemination, reuse and collaboration in science and scholarship.
On July 15 2020, cOAlition S announced their Rights Retention Strategy, providing authors with the right to share the accepted manuscript (AAM) of their research articles with an open license and without embargo, as one of the ways to comply with Plan S requirements. This raises the question to what extent immediate and open licensed self archiving of scholarly publications is currently already possible and practiced. Here we provide the results of some analyses carried out earlier this year, intended to at least partially answer that question. We limit this brief study to journal articles and only looked at CC-BY licenses (not CC0, CC-BY-SA and CC-BY-ND, which can also meet Plan S requirements).
Basically, there are two possible approaches to inventorize journals that currently allow immediate green archiving under a CC-BY license:
- policy-based – by checking journal- or publisher policies, either directly or through Sherpa Romeo or Share Your Paper from Open Access Button.
- empirically – by checking evidence for green archiving with 0 embargo and CC-BY license (with potential cross-check against policies to check for validity).
Here we only report on the first approach.
A full overview of journal open access policies and allowances (such as will be provided by the Journal Checker Tool that cOAlition S announced early July 2020) was beyond our scope here. Therefore, we carried out a policy check for a limited set of 36 large publishers to get a view of currently existing options for immediate green archiving with CC-BY license, supplemented with anecdotal data on journals that offer a compliant option. We also briefly discuss the potential and limitations of an empirical approach, and potential publisher motivations behind (not) allowing immediate sharing and sharing under a CC-BY license, respectively.
Our main conclusions are that:
- Based on stated policies we found very few (18) journals that currently allow the combination of immediate and CC-BY-licensed self archiving.
- Based on stated policies of 36 large publishers, there are currently ~2800 journals with those publishers that allow immediate green, but all disallow or do not explicitly allow CC-BY.
Large publishers – policies
We checked the 36 largest non-full-OA publishers, based on number of 2019 articles according to Scilit (which uses Crossref data), for self archiving policies allowing immediate sharing on (institutional) repositories. Of these 36 publishers, 18 have zero embargo allowances for at least some of their journals for green sharing of AAMs from subscription (incl. hybrid) journals in institutional or disciplinary repositories. Overall that pertains to at least 2785 journals. Elsevier only allows this in the form of updating a preprint shared on ArXiv or RePEc. From these large publishers, those with the most journals allowing zero embargo repository sharing are Sage, Emerald, Brill, CUP, T&F (for social sciences), IOS and APA. Notably, though not a large publisher in terms of papers or journals, the AAAS also allows immediate sharing through repositories.
None of these policies allow using a CC-BY license for sharing in repositories. Three explicitly mention another CC-license (NC or NC-ND), others do not mention licenses at all or ask authors to state that the copyright belongs to the publisher. Sometimes CC-licenses are not explicitly mentioned, but it is indicated that the AAM shared in repositories are for personal and/or non-commercial use only.
For the data see columns F-H in the tab ‘Green OA‘ in the accompanying spreadsheet.
Other evidence
From the literature and news sources we know of a few examples of single publishers allowing zero embargo sharing in repositories combined with a CC-BY license:
- ASCB:
- Molecular Biology of the Cell (PV OA (CC-BY) after 2 months,
AAM 0 embargo with CC-BY)
- Molecular Biology of the Cell (PV OA (CC-BY) after 2 months,
- MIT Press:
- Asian Development Review (full OA but PV has no open license)
- Computational Linguistics (full OA but PV=CC-BY-NC-ND)
- Microbiology Society
- Microbiology
- Journal of general Virology
- Journal of medical Microbiology
- Microbial genomics
- International Journal of Systematic and Evolutionary Microbiology
- JMM case reports
- Royal Society
- Biology Letters
- Interface
- Interface Focus
- Notes and records
- Philosophical Transactions A
- Philosophical Transactions B
- Proceedings A
- Proceedings B
A check of the long tail of smaller publishers could yield additional examples of journals compliant with 0 embargo / CC-BY sharing from smaller publishers.
Empirical analysis of green archiving
Empirical analysis of actual green archiving behaviour (e.g. using Unpaywall and/or Unpaywall data in Lens.org) could also provide leads to journals allowing early sharing.
Since Unpaywall data do not contain information on the date a green archived copy was made available in a repository, a direct empirical analysis of zero-embargo archiving is not readily possible. As a proxy, a selection could be made of articles published in a period of 3 months before a given database snapshot, and then identifying those that are only available as green OA. A period of 3 months, rather than 1 month or less, would allow for some delay in posting to a repository.
The benefit of using Lens.org for such an analysis is the availability of a user-friendly public interface to perform queries in real time. The disadvantage is that, although Lens sources OA information from Unpaywall, no license information for green OA is included, and no distinction is made between submitted, accepted and published versions. Analyses could also be done on a snapshot of the Unpaywall database directly, which includes license information for green OA (where available) and provides version information.
Gap analysis report
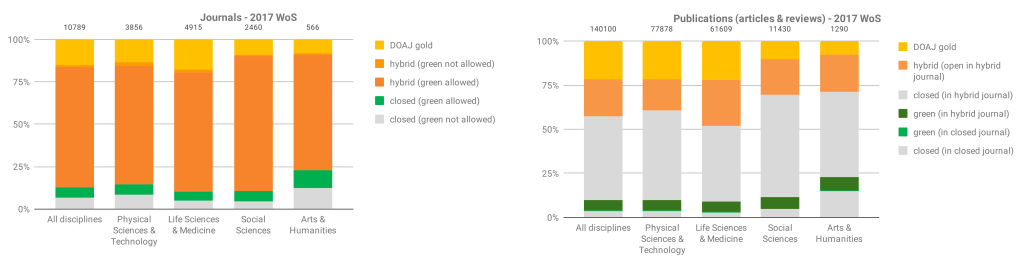
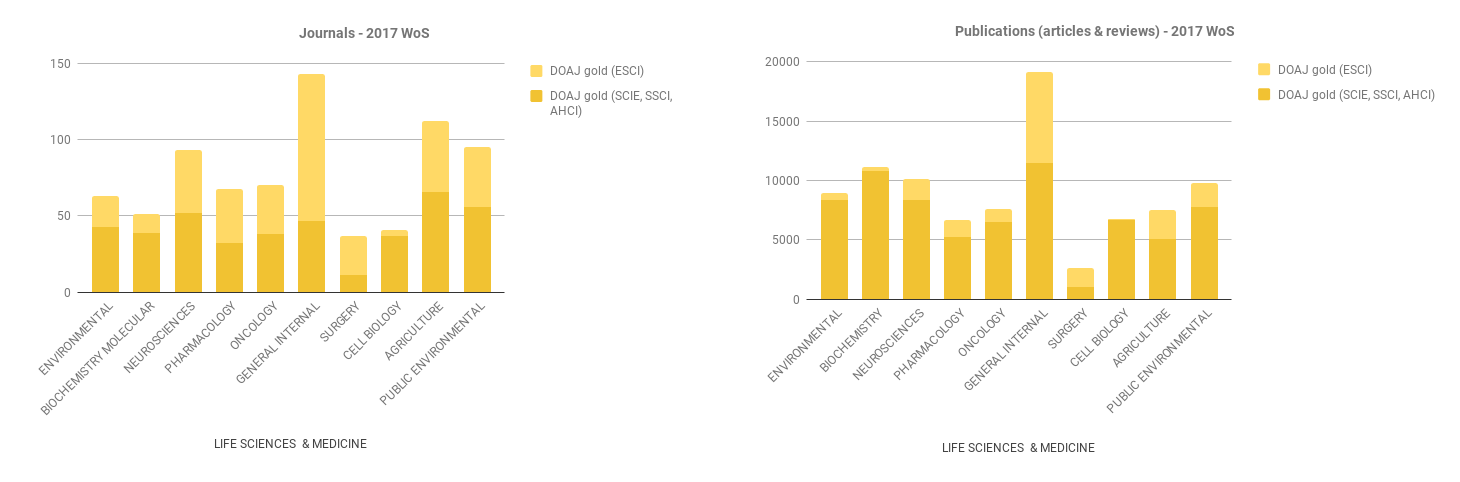
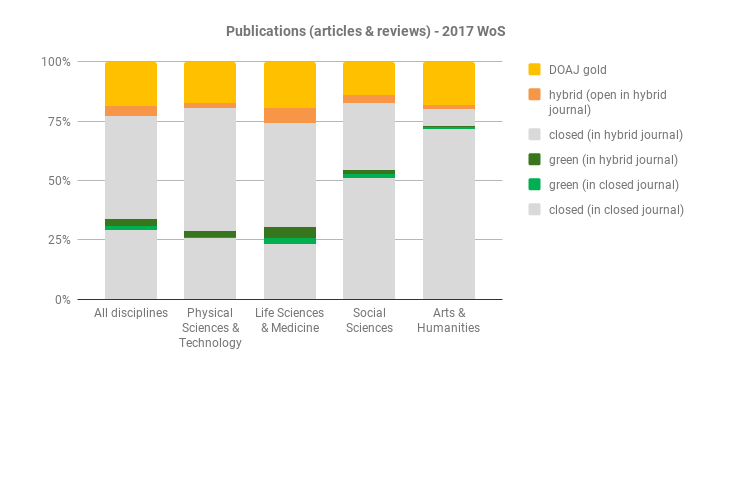
In our previous gap analysis report that gave a snapshot of publication year 2017, we did harvest policies from Sherpa Romeo systematically for the subset of journals included in the gap analysis (journals in Web of Science publishing articles resulting from Plan S-funded research). As explained above, updating this approach was beyond our scope for this exercise.
In our original gap analysis data, we found no examples of journals that allowed 0 embargo in combination with CC-BY.

(source: Open access potential and uptake in the context of Plan S – a partial gap analysis)
Potential publisher motivations
From checking policies and behaviour, different publisher approaches emerge regarding embargoes and licenses for self-archived article versions. It seems that the reluctance of publishers to allow immediate sharing is weaker overall than the reluctance to allow CC-BY for green OA. That may have to do with the reasons behind these two types of reluctance.
The reason to not allow immediate sharing may concern fears of losing subscription income and perhaps also a dwindling effect on visitors to their platform. However, several publishers have noticed that this fear may be ungrounded, as libraries do not unsubscribe yet just because some percentage of articles is also immediately available as AAM, not only because of incomplete open availability but also because of the wish to provide access to published versions in their platform context. Some publishers (e.g. Sage) have also publicly stated that they do not witness a negative effect on subscriptions.
For the reluctance to allow CC-BY licenses we expect other reasons to be at play, primarily the desire to be in control over how, where and in what form content is shared. This relates to protecting income from derivative publications (reprints, printing-on-demand, anthologies etc.) and also to preventing others having any monetary gain from including content on competing platforms.
Another aspect is the inability of publishers to require linking back to the publisher version in cases where the CC-BY licensed AAM in the repository is reused, rather than depending on community norms to provide information on and links to various versions of a publication.
Looking at the empirical evidence and these considerations, it can potentially be expected that across publishers, a move towards shorter embargoes might be easier to achieve than a move towards a fully open license for green-archived versions. It should be noted that while there are examples of publishers allowing shorter embargoes in response to specific funder mandates (e.g from Wellcome, NIH), to our knowledge there has not, prior to Plan S, been funder or institutional pressure to require open licenses for green archived AAMs. Thus, it will remain to be seen whether publishers would be inclined to move in this direction in response. The reactions to the letter cOAlition S sent to a large number of publishers to inform them on the cOAlition S Rights retention Strategy should provide clarity on that.
In addition to funder policies, institutions and governments could further support this development through policies and legislation relating to copyright retention, as well as zero embargoes and licenses for green OA archiving of publications resulting from publicly funded research. This could provide authors with more rights and put pressure on publishers to seriously reconsider their stance on these matters.


































{kind=link}